

I pointed out recently that although La La Land is a romance, the movie opens with cars. The semiconductor industry is like that, too—no matter which way you turn it is automotive. It may not show yet in manufacturing volume and revenue, since it is about 10% of the market. However, the newer parts of automotive, those associated with autonomous driving, have ~30% growth rates (which is close to doubling every two years, by the rule of 70). There are several really big changes, such as automotive Ethernet or security, which I won’t discuss today. But probably the biggest change is the need for vision processing.
There are two separate reasons that this is such a big change. Firstly, vision processing has to be done on-vehicle. The amounts of data are insanely large, too large to upload to the cloud for processing. But more fundamentally, a vehicle cannot require network connectivity to decide whether a light is green or red, or whether that thing ahead is a pedestrian or a mailbox. This is a level of computation that cars have never required before, so is a challenge for the automotive semiconductor ecosystem. The traditional suppliers don’t understand high-performance processors and leading-edge processes. The mobile semiconductor ecosystem does, but it doesn’t understand automotive reliability and only recently heard the magic number 26262.
 (For more on ISO 26262, see my recent post “The Safest Train Is One That Never Leaves the Station”. For an introduction to convolutional neural nets (CNN), see Why is Google So Good at Recognizing Cats?. Also, last year Cadence ran a seminar in Vegas that I wrote up in a full week of posts here, starting on Monday with Power Efficient Recognition Systems for Embedded Applications.)
(For more on ISO 26262, see my recent post “The Safest Train Is One That Never Leaves the Station”. For an introduction to convolutional neural nets (CNN), see Why is Google So Good at Recognizing Cats?. Also, last year Cadence ran a seminar in Vegas that I wrote up in a full week of posts here, starting on Monday with Power Efficient Recognition Systems for Embedded Applications.)
The second change is with vision processing itself. If you go back only a few years, vision processing was algorithmic, with the focus of research on edge-detection algorithms, building 3D models from 2D data, and so on. Now the whole field has switched to convolutional neural nets (CNN). But it is not just vision processing that has gone neural, a lot of the decision processing has, too. Arguably, vision processing has advanced more in the last two to three years then since…cue dramatic music…the dawn of time.
Embedded Vision Summit
embedded vision summit badgeToday is the start of this year’s Embedded Vision Summit, and will run at the Santa Clara Convention Center until May 3. For details, click on the logo to the right. If you are going, I will see you there.
Over the past five years, the summit has grown from a small meet-up to a must-attend industry event with 80 speakers, 50 exhibitors, and over 1,000 attendees. Those numbers are an indication of the growing interest and importance of vision. Their tagline says why. It is “the event for innovators who want to bring visual intelligence into products.” These technologies will revolutionize transportation, but also lead to things like security cameras that can tell the difference between your kids fighting and a thief, or drones that can follow you skiing through the trees.
Tensilica Vision C5 DSP for Neural Network Processing
 It has been said that the only predictable thing about the British weather is its unpredictability. Well, the only predictable things about neural networks is that they will change. Obviously the highest performance per watt comes from designing with RTL (or perhaps even gates). But this is also the least amenable to change. The easiest to change is pure software, just run neural network code on the main CPU. But that has no chance of achieving either the performance or the power budget. A specialized programmable neural network processor is the Goldilocks level, neither too not nor too cold, programmable but high performance per watt.
It has been said that the only predictable thing about the British weather is its unpredictability. Well, the only predictable things about neural networks is that they will change. Obviously the highest performance per watt comes from designing with RTL (or perhaps even gates). But this is also the least amenable to change. The easiest to change is pure software, just run neural network code on the main CPU. But that has no chance of achieving either the performance or the power budget. A specialized programmable neural network processor is the Goldilocks level, neither too not nor too cold, programmable but high performance per watt.
To give you an idea of just how fast things are changing, in 2012 AlexNet was the best recognition system requiring 724M MACS/image. Today, RESNET-152 requires over 11B (and, of course, gets better results from all that work). But that highlights a big challenge for people designing products today: how to pick an inference platform in 2017 for a product shipping in 2019 and perhaps for several years afterwards. It has to have all three of high performance, low power, and programmability. Picking any two of the three is easy, but they all work against each other, so hitting the sweet spot requires a core designed to do all three.
Today, Cadence is announcing just that, the newest member of the Tensilica family, the Vision C5, which is a neural network DSP. It is targeted at vision, lidar, voice, and radar applications in the mobile, surveillance, automotive, drone, and wearable markets. It has a computational capacity of 1TeraMAC/s (trillion multiply-accumulate operations per second). It is not an accelerator, it is a standalone self-contained neural network DSP. This is important since accelerators only handle part of the problem, requiring a lot of processing power on whatever other processor is in use to do the rest. For example, they may only handle the convolutional (first) step of a CNN, which in addition to only partially offloading the computation, means that a lot of bandwidth is going to be used shifting data back and forth. The Vision C5 DSP completely offloads all the processing and minimizes the data movement, where much of the power is actually consumed.
Typically, neural network applications are divided into two phases, training and inference. The training is normally done in the cloud and requires processing large sets of data requiring 1016 to 1022 MACs per dataset. Inference usually runs closer to the edge of the network, in the drone or car for example. Each image requires 108 to 1012 MACs. The biggest issue, though, is power. It is this inference phase of using neural networks where the Vision C5 DSP is focused.
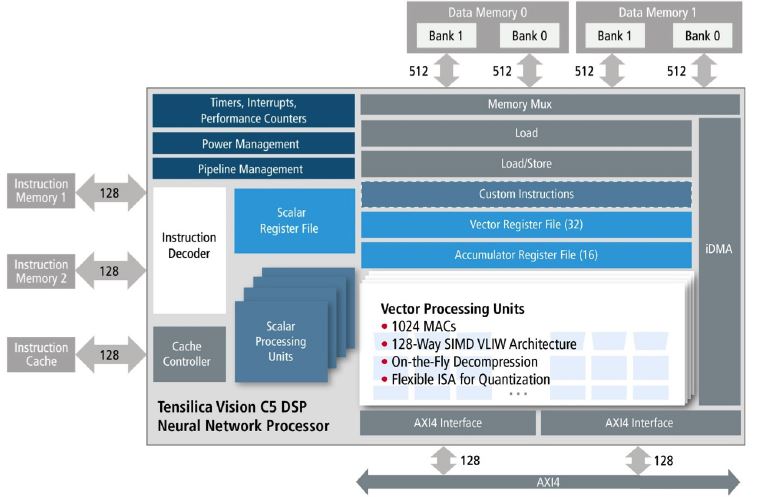
vision c5 dsp block diagramThe Vision C5 DSP neural network processor is:
A complete, standalone DSP that runs all layers of CNN (convolution, fully connected, normalization, pooling…)
A DSP for the fast-changing neural network field: programmable and future-proof
Performance of 1 TMAC/s (trillion multiply-accumulates per second)
1024 8-bit MACs or 512 16-bit MACs for exceptional performance at both resolutions
128-way, 8-bit SIMD or 64-way, 16-bit SIMD VLIW architecture
Not a hardware accelerator to pair with a vision DSP, rather a dedicated neural network optimized processor
Architected for multi-processor design—scales to multi-TMAC/s solutions
Same proven software tool set as the Vision P5 and P6 DSPs
<1mm2 in 16nm
vision c5 software flowWonderful hardware is not a lot of use if it is too difficult to program. There are standard open-source CNN frameworks such as Caffe and TensorFlow that are the most common way to develop in the space. These flow cleanly into the CNN mapper and then all the way down to the Vision C5 DSP.
Summary
The Vision C5 is targeted at high-performance CNN applications that require TMAC/s operation. For lower performance, such as the neural nets that are occasionally required in mobile, the Vision P6 DSP is more appropriate, with a performance of up to 200 GMAC/s. For the most demanding applications, multicore versions of the Vision C5 DSP fit the bill.









